
How to Avoid A/B Test Bias for Reliable Results
Most American marketers trust A/B tests to guide business decisions, yet even the most sophisticated experiments can fall victim to invisible bias. Research shows that hidden errors can quietly skew results, leading teams to act on unreliable insights. Understanding where these biases come from is critical for any American brand that depends on digital testing for growth. This article sheds light on the real sources of test bias, common misconceptions, and the methods experts use to safeguard data integrity.
Table of Contents
- A/B Test Bias Defined and Misconceptions
- Main Types of Bias in A/B Testing
- Key Steps to Prevent Sampling Bias
- Ensuring Data Integrity and Validity
- Common Pitfalls and How to Avoid Them
Key Takeaways
| Point | Details |
|---|---|
| A/B Testing Bias | Systematic errors and unexpected influences can skew results, affecting the reliability of insights from A/B testing. |
| Preventing Sampling Bias | Implementing randomization techniques and clear participant selection criteria is essential for obtaining representative data. |
| Maintaining Data Integrity | Robust data collection and validation methods, along with ethical considerations, are crucial for trustworthy experimental results. |
| Recognizing Common Pitfalls | Awareness of biases like confirmation and selection bias can aid in developing strong testing methodologies that yield genuine insights. |
A/B Test Bias Defined and Misconceptions
A/B testing promises objective insights, but hidden biases can silently distort your results. Test bias occurs when systematic errors or unexpected influences skew experimental data, rendering conclusions unreliable or misleading. These subtle distortions can emerge from numerous sources, transforming seemingly precise measurements into statistical mirages.
Understanding these biases requires recognizing their complex origins. Model interference in online experiments reveals how underlying algorithmic interactions can introduce unexpected skews. Researchers have identified scenarios where machine learning models interact in ways that contaminate test results, creating what statisticians call "symbiosis bias" - a phenomenon where shared data between competing algorithms generates false performance signals.
Common misconceptions about A/B testing often stem from oversimplified assumptions. Many marketers and product managers believe that randomization alone guarantees unbiased results. However, true experimental integrity demands more nuanced approaches. Potential bias sources include:
- Sampling errors: Nonrepresentative participant groups
- Temporal variations: Time-dependent fluctuations in user behavior
- Interaction effects: Unexpected cross-group contamination
- Selection bias: Skewed participant recruitment methods
Navigating these challenges requires a sophisticated, multi-layered approach to experimental design. By acknowledging potential biases and implementing robust statistical controls, researchers can develop more accurate, trustworthy A/B testing methodologies that deliver genuine insights into user behavior and performance metrics.
Main Types of Bias in A/B Testing
Bias in A/B testing represents systemic errors that can dramatically undermine experimental validity. Understanding these distortions is critical for marketers and product managers seeking reliable insights. Heavy-user bias emerges as a particularly significant statistical challenge, where disproportionate participation from most active users can skew entire experimental results.
The landscape of A/B testing bias is complex and multifaceted. Different types of bias can infiltrate experiments at various stages, each presenting unique challenges to data integrity. Researchers have identified several primary bias categories that consistently compromise testing accuracy:
- Selection Bias: Occurs when participant groups are not truly randomized
- Confirmation Bias: Researchers unconsciously interpreting data to match preexisting expectations
- Survivorship Bias: Focusing only on successful test subjects while overlooking failures
- Novelty Effect: Temporary engagement increases due to something being new, not inherently better
- Simpson's Paradox: Statistical trends that reverse when data is aggregated differently
Navigating these potential pitfalls requires sophisticated experimental design and statistical awareness. By anticipating and proactively addressing these biases, researchers can develop more robust testing methodologies that generate genuinely actionable insights. Careful sampling, rigorous randomization, and continuous statistical validation become essential strategies for maintaining experimental integrity and extracting meaningful performance data.

Key Steps to Prevent Sampling Bias
Sampling bias represents one of the most insidious threats to A/B testing reliability, potentially rendering entire experiments invalid. Researchers must implement strategic approaches to minimize these statistical distortions and ensure representative data collection. Developing a theoretical framework for sample splitting provides critical guidance for designing experiments that maintain statistical integrity.
Preventing sampling bias requires a multifaceted approach that addresses potential contamination at every experimental stage. Key strategies include:
-
Randomization Techniques
- Use stratified random sampling
- Implement block randomization
- Ensure true random assignment across test groups
-
Sample Size Considerations
- Calculate statistically significant sample sizes
- Avoid convenience sampling
- Maintain consistent sample distribution
-
Participant Selection
- Define clear inclusion and exclusion criteria
- Minimize self-selection effects
- Balance demographic representation
Interference bias poses another significant challenge, particularly in complex digital environments. Marketers and researchers must remain vigilant about potential cross-contamination between test groups that could skew results. This means carefully controlling experimental conditions and understanding how different user segments might interact with test variations.

Ultimately, preventing sampling bias demands continuous monitoring and a disciplined approach to experimental design. By implementing rigorous statistical controls, transparently documenting methodologies, and remaining skeptical of seemingly straightforward results, researchers can develop more robust and trustworthy A/B testing protocols that generate genuinely actionable insights.
Ensuring Data Integrity and Validity
Maintaining data integrity is the cornerstone of reliable A/B testing, requiring meticulous attention to experimental design and ethical considerations. Ethical frameworks in online controlled experiments highlight the critical importance of transparency and fairness throughout the research process, emphasizing that statistical validity extends far beyond mere numerical calculations.
Comprehensive data integrity involves multiple interconnected strategies that address potential vulnerabilities at every experimental stage. Researchers must implement robust mechanisms to protect against common integrity threats:
-
Data Collection Protocols
- Establish clear documentation procedures
- Implement standardized data recording methods
- Create unambiguous tracking mechanisms
-
Validation Techniques
- Cross-reference multiple data sources
- Use statistical significance tests
- Conduct independent verification
-
Ethical Considerations
- Obtain informed participant consent
- Protect participant privacy
- Ensure transparent reporting of methodologies
The complexity of modern digital environments introduces additional challenges in maintaining experimental validity. Researchers must develop sophisticated approaches to mitigating symbiosis bias, particularly in recommendation algorithm testing, where interconnected systems can produce misleading results.
Ultimately, data integrity is not a one-time achievement but a continuous commitment. By cultivating a culture of rigorous methodology, transparent reporting, and constant skepticism, researchers can build trust in their experimental outcomes and generate insights that drive meaningful decision-making across digital platforms.
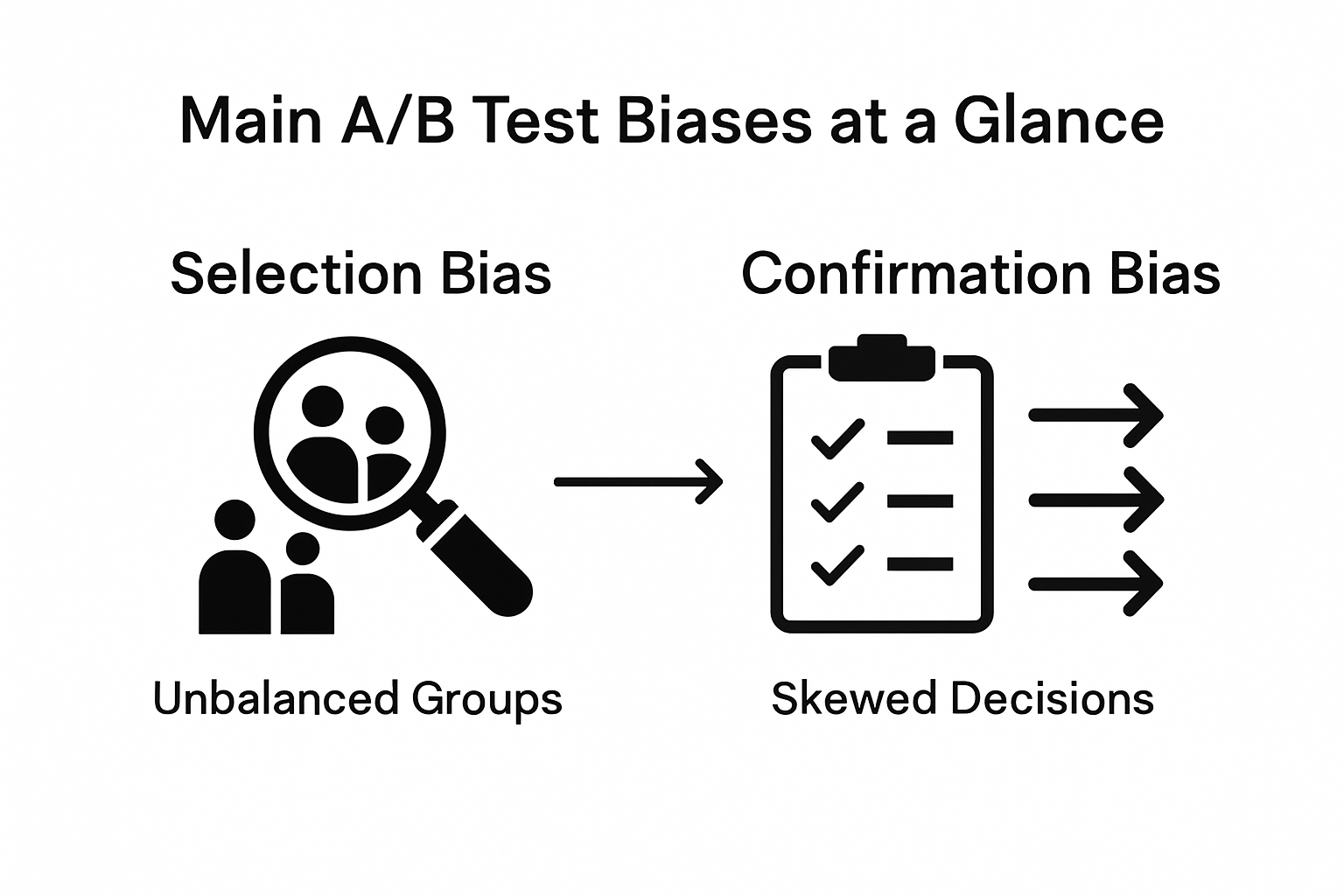
Common Pitfalls and How to Avoid Them
A/B testing can quickly become a minefield of statistical traps that compromise experimental integrity. Understanding the common biases that skew experimental results represents the first critical step in developing robust testing methodologies. Researchers and marketers must remain vigilant against subtle distortions that can transform seemingly objective data into misleading conclusions.
The most prevalent pitfalls in A/B testing emerge from psychological and statistical blind spots that unconsciously influence experimental design and interpretation. These critical challenges include:
-
Confirmation Bias
- Unconsciously seeking data that validates preexisting beliefs
- Overlooking contradictory evidence
- Prematurely drawing conclusions
-
Selection Bias
- Choosing non-representative participant groups
- Failing to randomize test subjects effectively
- Introducing unintended demographic skews
-
Novelty Effect
- Mistaking initial enthusiasm for genuine improvement
- Failing to distinguish between short-term excitement and long-term performance
- Neglecting sustained user engagement metrics
Understanding these pitfalls requires more than theoretical knowledge. Practitioners must develop a disciplined approach that systematically identifies and mitigates potential experimental distortions. Recognizing the five core biases that compromise A/B testing provides a strategic framework for maintaining statistical rigor.
Successful A/B testing demands constant skepticism and a commitment to methodological integrity. By anticipating potential biases, implementing robust validation techniques, and maintaining a critical perspective, researchers can transform statistical challenges into opportunities for genuine insight generation.
Achieve Truly Reliable A/B Test Results Without the Guesswork
Avoiding bias is critical for trustworthy A/B testing. When you face challenges like sampling errors, selection bias, or the novelty effect, your decisions can be based on misleading data instead of real user behavior. This article highlights these common pitfalls and stresses the need for rigorous methods to maintain data integrity and accuracy.
Stellar offers a solution designed exactly for marketers and growth hackers seeking precise, bias-resistant experiments. Our A/B Testing Tool features a no-code visual editor and advanced goal tracking that minimize errors from improper sampling or interaction effects. With real-time analytics and a lightweight script of only 5.4KB, Stellar ensures minimal impact on website performance while delivering actionable insights that truly reflect user engagement.
Ready to eliminate guesswork from your testing process and build confidence in your results?
Explore how easy it is to conduct robust, bias-aware A/B tests with Stellar’s platform. Start your free plan today, especially if your business tracks under 25,000 users monthly, and empower your growth with the fastest, simplest tool that keeps your data honest and decisions sharp.
Frequently Asked Questions
What are common sources of bias in A/B testing?
Bias in A/B testing can arise from several sources, including selection bias (non-random participant groups), confirmation bias (interpreting data to fit preexisting beliefs), survivorship bias (only focusing on successful outcomes), novelty effect (temporary increases in engagement due to newness), and Simpson's Paradox (misleading statistical trends across different data aggregations).
How can I prevent sampling bias in my A/B tests?
To prevent sampling bias, use randomization techniques such as stratified or block random sampling, ensure sufficient sample sizes for statistical significance, and define clear inclusion and exclusion criteria to minimize self-selection effects. Properly managing demographic representation is also crucial.
What is the novelty effect, and how does it impact A/B testing results?
The novelty effect occurs when users show increased engagement due to the newness of a product or feature, which may not translate into long-term success. It's essential to distinguish between initial excitement and sustained performance metrics to accurately assess the effectiveness of changes.
Why is data integrity important in A/B testing?
Data integrity is vital in A/B testing because it ensures that the experimental results are reliable and valid. Maintaining rigorous documentation, implementing standardized data collection methods, and protecting participant privacy are key aspects that contribute to the overall integrity of the data collected.
Recommended
Published: 12/14/2025